Reinforcement Learning in Practice
Key Concepts
Reinforcement Learning (RL) is an exciting branch of machine learning inspired by behavioural psychology, where algorithms learn by interacting with an environment. It has gained significant attention due to its ability to handle complex tasks, from playing board games like Go to real-world applications like robotics and financial trading. This article will explain the foundational concepts of RL to demystify this intriguing domain.
The Agent & Environment:
Imagine teaching a dog a new trick. You give commands, and the dog performs actions. If it does well, it gets a treat; if it doesn’t, it gets no reward or even a slight reprimand. In RL:
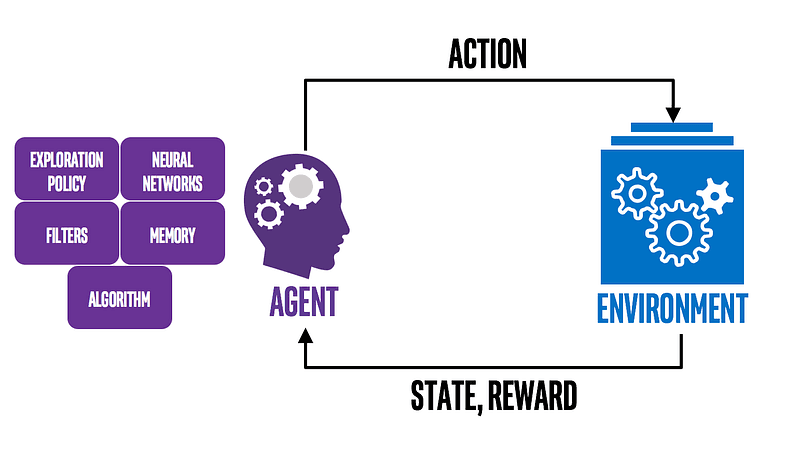
- Agent: The learner or decision-maker, akin to the dog.
- Environment: Everything the agent interacts with, which, in our analogy, includes you, the command, and the surroundings.
The agent takes actions in the environment, which then transitions to a new state and returns rewards as feedback to the agent.
State, Action, and Reward:
- State (s): The current scenario or situation the agent finds itself in.
- Action (a): The decisions or moves made by the agent in response to a state.
- Reward (r): The feedback the agent receives after acting in a state. It’s the agent’s immediate measure of how good or bad the action was.
Policy:
The policy is the agent’s strategy to determine the following action based on the current state. It can be deterministic (a direct mapping from state to action) or stochastic (giving probabilities of choosing various actions).
Value Functions:
- Value Function (V(s)): Represents the expected long-term reward with a discount for a given state. It tells us the worth of a state.
- Q-function (Q(s, a)): Represents the expected return of taking action in state s. This is pivotal for many RL algorithms, allowing the agent to evaluate each action in a given state.
Exploration vs. Exploitation Dilemma:
In the process of learning, an agent faces a fundamental challenge:
- Exploration: Trying new actions to discover their effects.
- Exploitation: Using known actions that yield the highest rewards.
Striking a balance is crucial. Too much exploration can result in unnecessary risks, while excessive exploitation can lead to missed opportunities.
Discount Factor:
The discount factor (γ) determines the present value of future rewards. A value of 0 makes the agent short-sighted, focusing only on immediate rewards, while a value close to 1 makes the agent prioritize long-term rewards.
Model-based vs. Model-free:
- Model-based: These methods try to predict what the environment will do next. It’s like playing chess and trying to anticipate your opponent’s moves.
- Model-free: These methods don’t care about the environment’s model. Instead, they focus on learning the value function or policy directly from experiences.
Learning Methods:
- Off-Policy: The agent learns the value of the optimal policy independently of the agent’s actions, e.g., Q-learning.
- On-Policy: The agent learns the value of the policy being carried out by the agent, e.g., SARSA.
What is Q-learning?
Q-learning is a model-free, off-policy RL algorithm that seeks to find the best action-selection policy for a given finite Markov decision process. It helps agents find the optimal strategy (or action) in every situation (or state) to achieve the maximum cumulative reward over time.
The Building Blocks of Q-learning
Q-table:
The heart of Q-learning lies in the Q-table, a matrix where rows represent states and columns represent possible actions. The value in each cell (denoted as Q(s, a)) represents the expected future reward for taking action an in state s.

